Details
-
Feature Request
-
Resolution: Unresolved
-
 Major
Major
-
None
-
High
Description
Below are a few remarks concerning the addition of a genetic algorithm to OptaPlanner. The remarks are based on the experience of building a prototype of a genetic algorithm for Planner (which can be found here: https://github.com/elsam/optaplanner).
1) The first problem was encountered while implementing the crossover operation. In order to be able to perform crossover, corresponding entities from different solutions have to be recognized. To solve this problem I created a temporary hack which involved changing the actual problem domain of the planning problems. Every entity needs an id which stays the same for corresponding entities after cloning the solution. Instead of implementing the Solution interface, solutions now implement an Individual interface which defines methods for finding entity id's for entity objects and vice versa.
The creation and maintainance of entity id's could probably be done by OptaPlanner itself if and only if it has control over the cloning procedure.
(A more detailed discussion can be found here: https://docs.google.com/document/d/1glxjbzqZ_an6D98ZBaVVSuNLPelJ16w2mqcjmwagZkU)
2) While implementing the support for the different score calculation methods I ran into another problem. During the execution of a genetic
algorithm, solutions get cloned constantly, and the score for a solution
is only calculated once or twice each generation. Which means that in order to profit from incremental score calculation, the IncrementalScoreCalculator needs to be cloned (DroolsScoreCalculator too). The problem with this is that many incrementalScoreCalculators contain references to planningEntities. So when both the solution and incrementalScoreCalculator are cloned, the duplicated incrementalScoreCalculator will still contain references to the old solution instead of the new one, making the score invalid.
This problem is also (temporary) solved using the entity id's mentioned in the previous point: instead of using direct references to entities, the incrementalScoreDirector contains the id's of the entities. The actual entities can then be requested from the (right!) solution when necessary. This shows that the solution to problem one is not a real solution: the user needs to know the existing of id's for the entities in order to be able to use them in the scorecalculation methods.
3) The moveselectors were used as mutation operator for the genetic algorithm (which is great because if they're improved for local search algorithms, they are too for genetic algorithms). There are however two problems with this approach:
A) The moveselectors act upon the workingSolution in the SolverScope. Genetic algorithms use multiple candidate solutions, which means that every time a move needs to be constructed for a different solution, this solution has to be set as current workingsolution and lifecycle events have to be triggered. Support for multiple solutions in the SolverScope and moveselectors are necessary.
B) Another problem concerning the moveselectors is the following. Whenever a move is permanently applied to a solution, all the entities and corresponding values are extracted from the problem domain (which is a time consuming process) in order to generate new moves. This is no problem for an algorithm like tabu search in which something like 8000 moves are constructed and evaluated before a permanent move is made and the extraction process is done all over again. However, in a genetic algorithm one move per individual per step is applied on average. This means that for changing the value of one variable of one entity, all entities and corresponding values have to be extracted.
==> maybe the fact the entities were already extracted for the crossover operation could help? (maybe those values could be saved)
The last problem is probably worse than it seems: for problems like TSP almost half of the execution time of the genetic algorithm is spent on extracting values from the domain in the moveselector in order to generate a single move.
4) In TSP another almost 25% of the time is spent on recreating the trailingEntityMap after solutions have been cloned.
Solution for problems 3B and 4: I think the solution to these problems can also be found using entity ids: Couldn't the entity id's and possible values for entities be saved in the solver itself once (and maybe updated when new entities and values are added)? The the logic of generating moves can be executed using the entity id's and finally when a move is generated, only the necessary values can be extracted from the solution. The trailing entity map could also make use of the id's. The cloning of the trailingEntityMap would be really fast because those maps can than be cloned when cloning a solution instead of reconstruction the map.
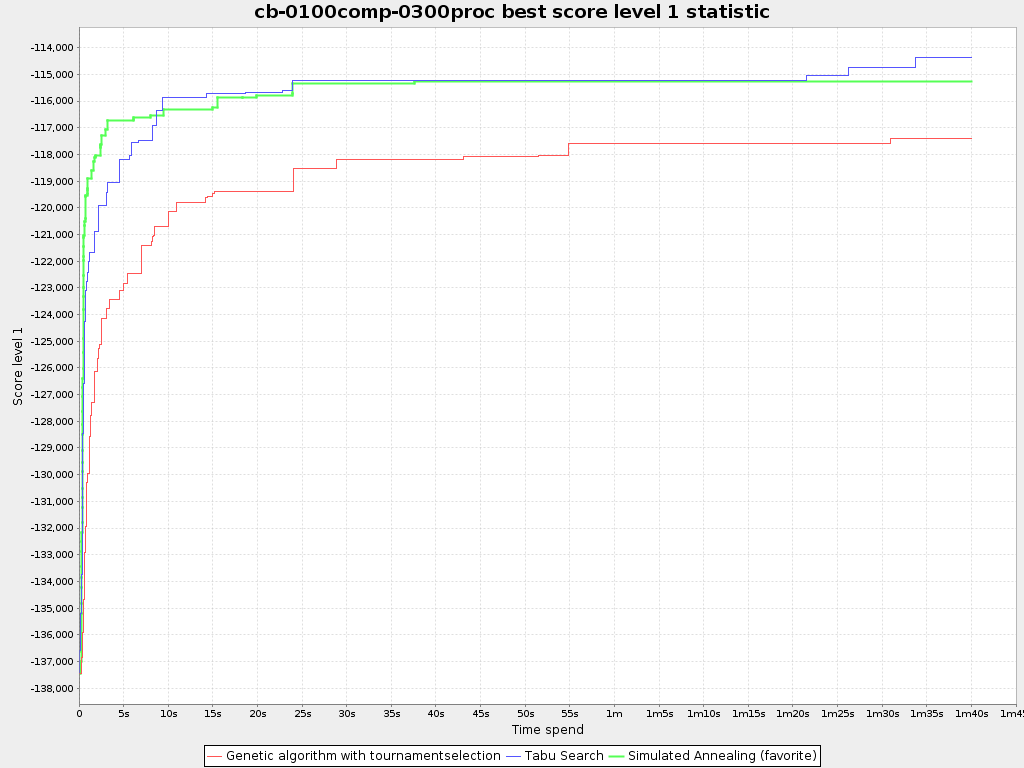
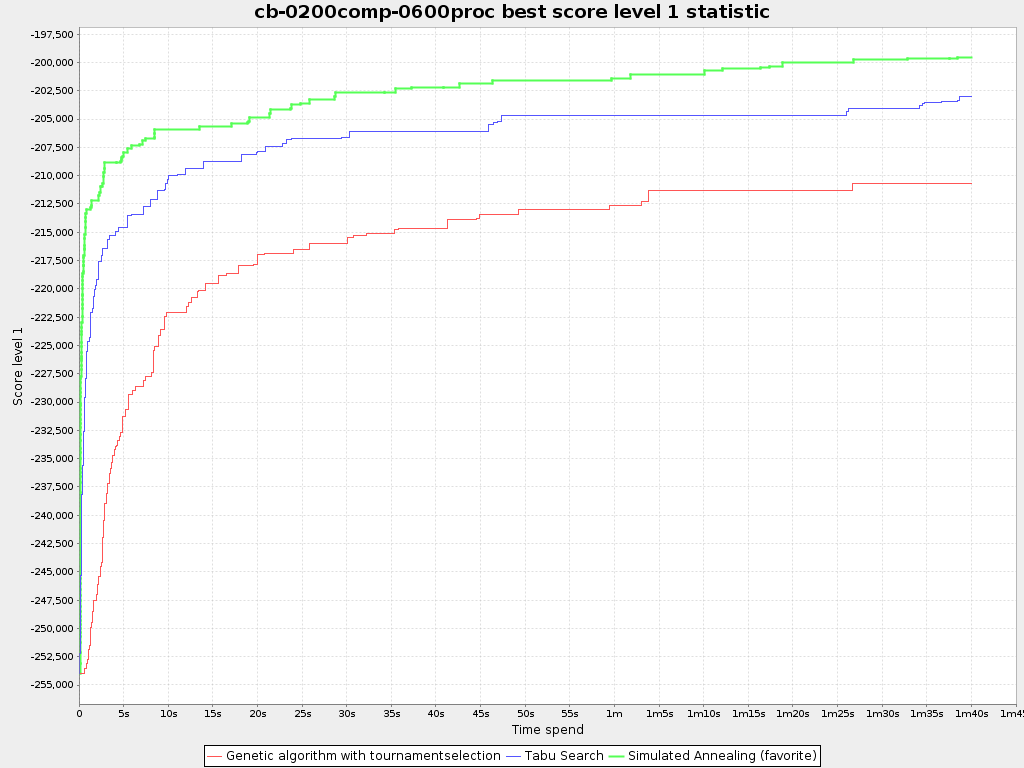
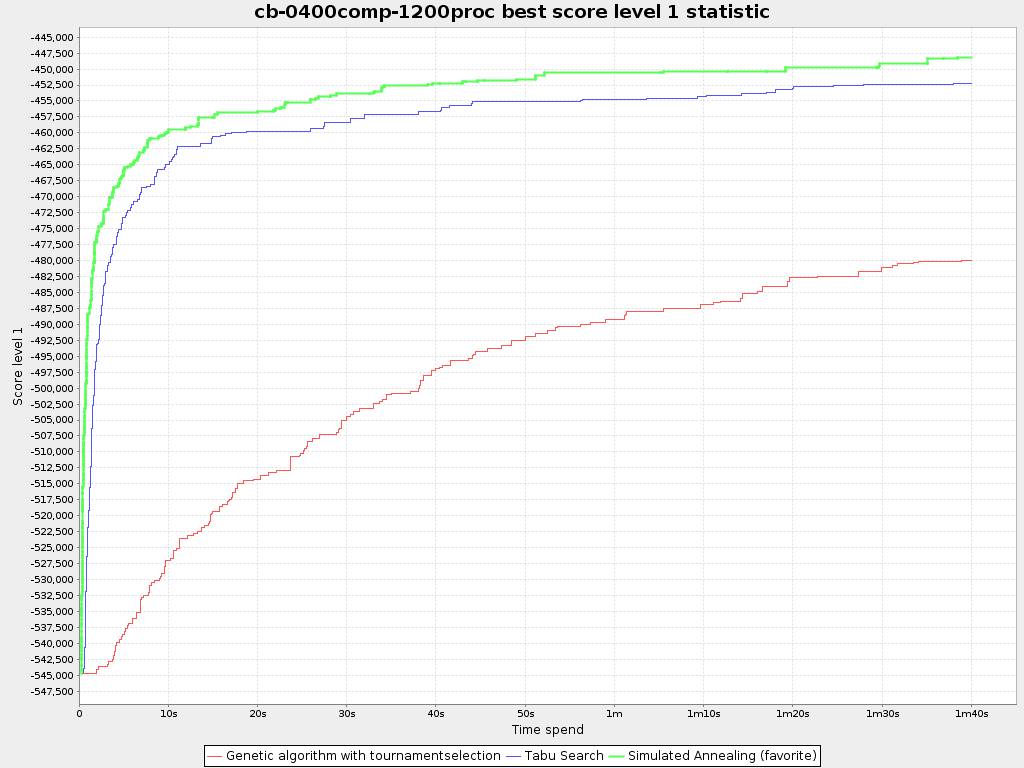
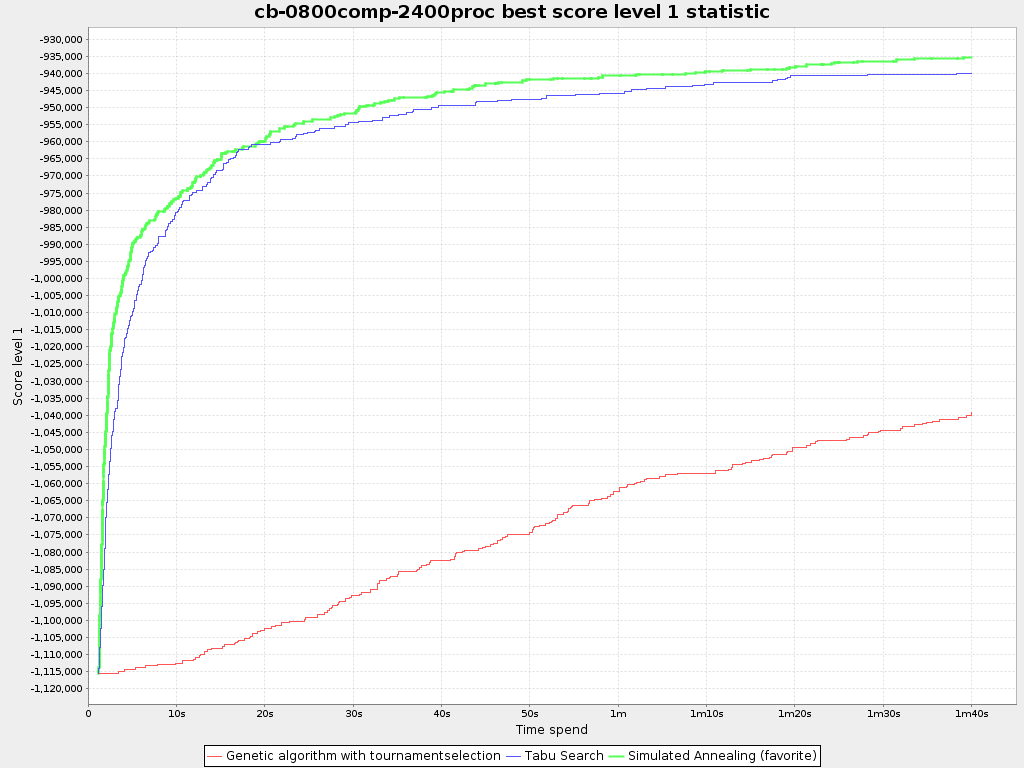
5) This problem is not really important in the first place but: For large problem instances the final score for the solution of the genetic algorithm is nowhere near the score of the solution using just a construction heuristic. The initial population of a genetic algorithm can only contain one solution generated by a construction heuristic as this solution is always the same. Otherwise, the diversity in the population goes down meaning the algorithm will converge really fast. But now, the other solutions are generated randomly, meaning a very bad initial solution. Because the single solution generated by a construction heuristic is so much better that the other individuals (which are randomly constructed), the other solutions wont survive very long and again all the diversity is gone and the algorithm is stuck at the solution generated by the construction heuristic.
A solution to this problem would be to create a stochastic construction heuristic, which generates fairly good individuals but still maintaining a lot of diversity (not every generated solution is the same). I've made an early draft of such a generic algorithm and will complete the description soon.